
Most AI voice products sound like a chatbot reading from a script. They are fast, technically correct, and completely devoid of warmth. JustListenly (https://www.justlistenly.com) was built with the opposite goal: a phone companion that people actually want to call again.
The founders came to us with a clear product vision -- an empathetic AI you can call any time, that remembers how you were feeling last time, and that never rushes you off the call. Our job was to turn that vision into a production system that could handle real subscribers, real payments, and real emotional conversations at scale.
Here is how we built it.
The Core Problem: Voice AI Latency Kills Empathy
The first challenge in any voice AI product is latency. When a human speaks to another human, a response arrives in roughly 200-400ms. When AI generates a response, processes it through a TTS engine, and sends audio back over a phone call, you are looking at 2-4 seconds if you are not careful.
A 3-second pause might be acceptable in a customer support bot. In an empathetic companion product, it destroys the feeling of being heard. The user says something vulnerable and hears silence. The magic evaporates.
We solved this with two techniques that work together:
- First-sentence-first TTS: The AI generates a full response, but we extract and send only the first sentence to ElevenLabs immediately. The caller hears a response in under 2 seconds. The remaining sentences follow as audio streams in.
- Static prompt pre-caching: Every repeated phrase -- menu prompts, greetings, transition phrases -- is pre-generated and cached. These play in under 5ms. There is zero wait on any IVR prompt the caller hears repeatedly.
The result: perceived latency dropped to under 2 seconds for new responses. Callers reported the conversation felt natural.
Phase 1: The Conversation Engine
Phase 1 was about getting the core call experience right. Nothing ships until a real person can pick up the phone, choose a companion, and have a conversation that feels human.
Persona Selection via IVR
Callers choose from four distinct companion personas -- Grandpa Jim, Grandma Grace, Mom Rose, and Dad Mike -- using their phone keypad. Each persona has a distinct voice profile on ElevenLabs and a tailored system prompt that shapes tone, vocabulary, and conversational style. Grandpa Jim talks differently than Mom Rose.
This single feature -- persona selection -- dramatically increases emotional connection. Users do not just call "an AI." They call their persona. Retention data supports this: users with a preferred persona return at higher rates than those who do not complete selection.
Conversation Quality Safeguards
Raw LLM output in a voice product creates two recurring problems: repetition and robotic phrasing. The AI loops back to the same comfort phrases. It uses formal language that does not match how people actually speak. Both problems were reported in early testing and both required engineering solutions, not just prompt tweaks.
We implemented three layers of conversational quality control:
- Repetition detection: Conversation history is scanned for recently used phrases. Any match triggers a prompt modifier that forces variation before the response is sent to TTS.
- Problem phrase filtering: A curated list of phrases that testers flagged as robotic or inappropriate is checked against every AI response before playback. Flagged responses are regenerated.
- Token and history limits: Shorter context windows force the AI to stay present in the current moment rather than circling back to earlier conversation threads.
Crisis Detection
A companion product that handles emotional conversations must handle crisis moments. The system monitors every caller utterance for crisis signals. On detection, the call immediately routes to the 988 mental health crisis line with no delay and no intermediate AI response. This is a hard requirement -- not a feature, a responsibility.
Phase 2: Subscriptions, Memory, and Business Operations
Phase 2 transformed a working product into a running business. The scope covered everything from payment processing to emotional memory to a full operations dashboard.
The Payment Architecture: Systeme.io + Stripe
The client's sales funnel runs on Systeme.io, but payment processing needed Stripe for reliability and subscription management. These two platforms do not share a native integration -- which created an interesting engineering problem.
The solution was a two-webhook architecture:
- Systeme.io fires a webhook when a sale is initiated. Our API receives it, resolves the plan from a query parameter, creates a Stripe Checkout Session, and returns a 302 redirect -- sending the user directly to Stripe's hosted checkout page.
- Stripe fires a webhook on payment completion. Our API receives the confirmed payment, creates the user record, issues session credits, and activates the subscription.
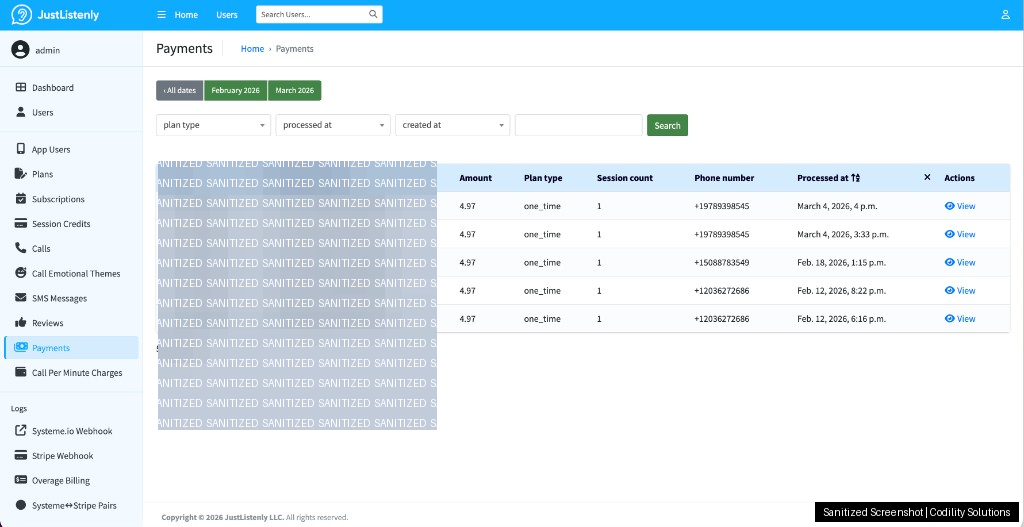
Because Systeme.io cannot inject metadata into Stripe sessions, we built a heuristic matching layer that pairs Systeme.io sale records with Stripe payment records by amount, currency, time window, and identity (email or phone). Every matched pair is logged and visible in the admin panel for verification.
The entire flow -- from a user clicking "Buy" on a Systeme.io landing page to having active session credits on their phone number -- is fully automated and auditable.
Session-Based Billing with Continuation Consent
Plans are session-based, not minute-based. A one-time plan gives 3-minute sessions. Monthly plans give 5-minute sessions. Credits are consumed at call start using FIFO ordering (oldest credits expire first). Monthly credits reset at each billing period. One-time credits do not expire.
Callers who want to keep talking past their session limit hear a soft prompt at 2:40 (one-time) or 4:40 (monthly). The prompt plays at 60% volume -- a gentle nudge, not an interruption. The caller must press 1 to explicitly consent to continuation billing at $0.97 per minute. Silence ends the call. No auto-charge, no surprise bills.
If a caller continues, overage charges are processed immediately via Stripe using the stored customer ID. Failed charges trigger a retry sequence with backoff and block the user from new calls until resolved.
Emotional Memory Across Calls
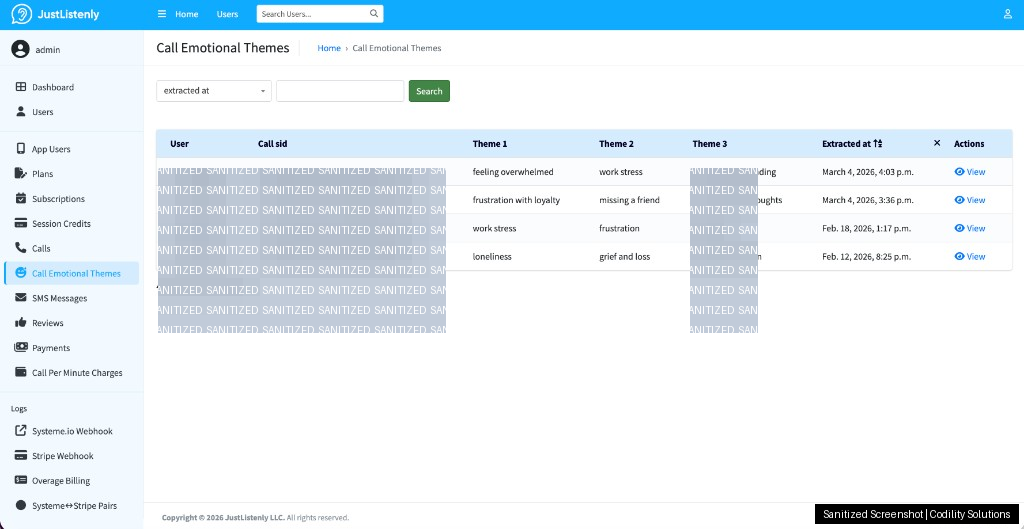
This is the feature that makes JustListenly feel different from every other AI voice product. After each call, OpenAI extracts 1-3 abstract emotional themes from the transcript -- things like "navigating a difficult family relationship" or "processing feelings of isolation." No names, no specifics, just themes.
At the start of the next call, those themes are surfaced to the AI with an optional acknowledgment: the companion can gently reference that it remembers the caller was going through something. The caller can decline to revisit it -- the system respects that choice completely.
The result is a product that feels like a relationship rather than a transaction. Callers are not starting from zero every time.
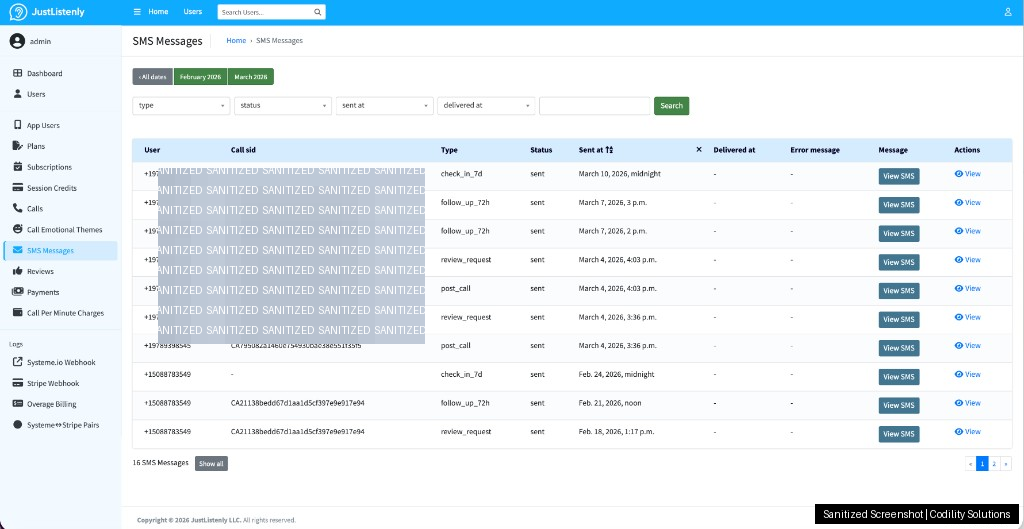
SMS Automation
Five automated SMS workflows run on the platform:
- Post-call message sent after every completed session
- Review request sent once per user lifetime (with a reward offer for completing it)
- 72-hour follow-up for users who have not called back
- 7-day check-in for longer-inactive users
- STOP keyword handling for immediate opt-out
All SMS activity is logged, searchable, and manageable from the admin panel. The client can send manual messages to individual users without touching code.
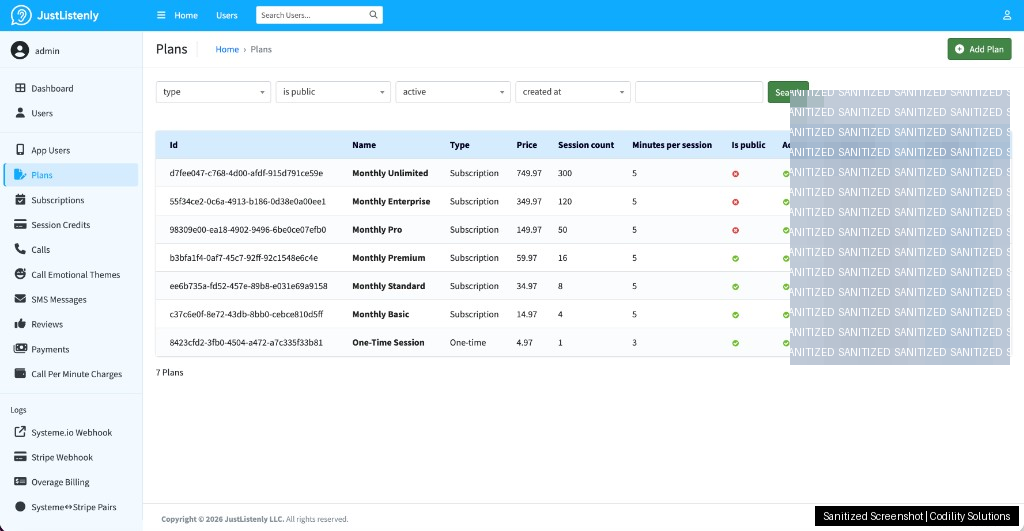
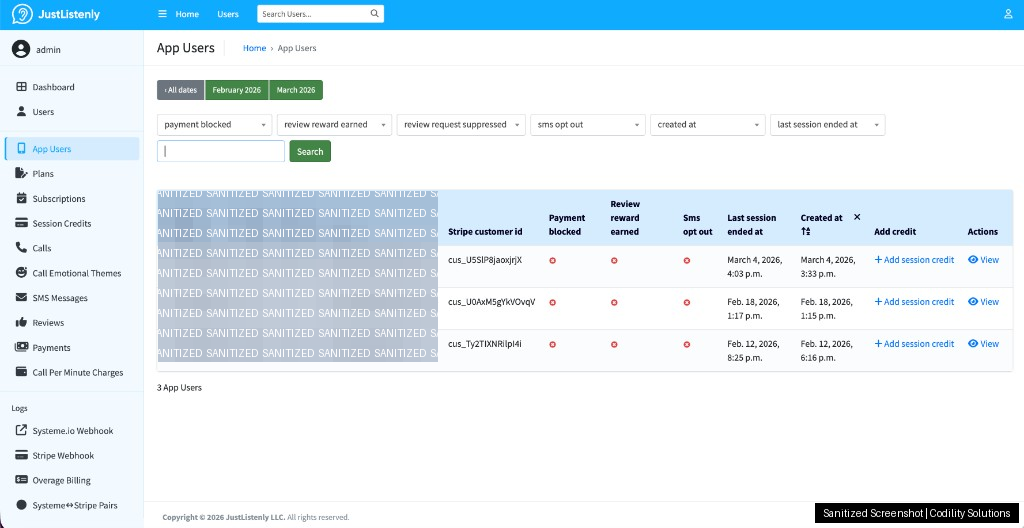
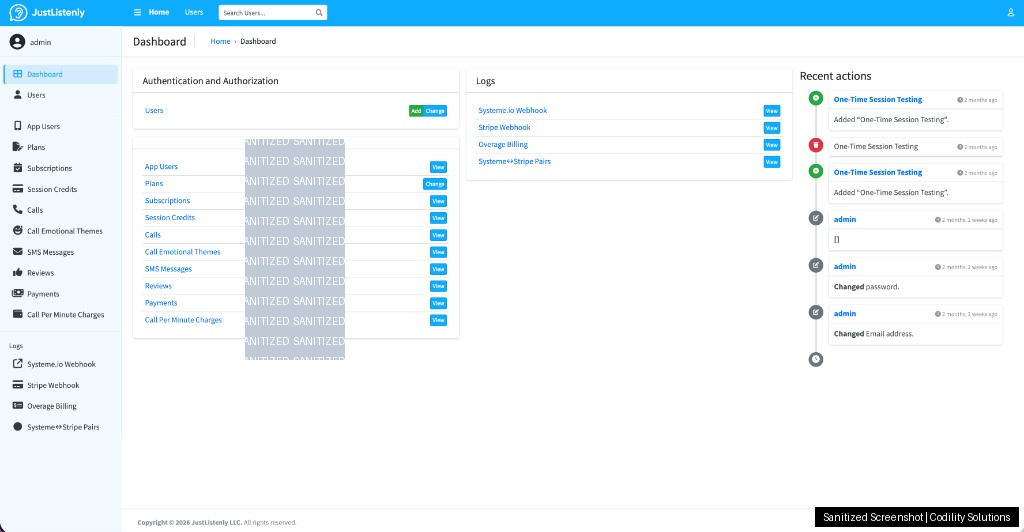
The Django Admin Panel
Non-technical operators need to run a live product. We built a full Django admin panel as the operations hub. Key capabilities:
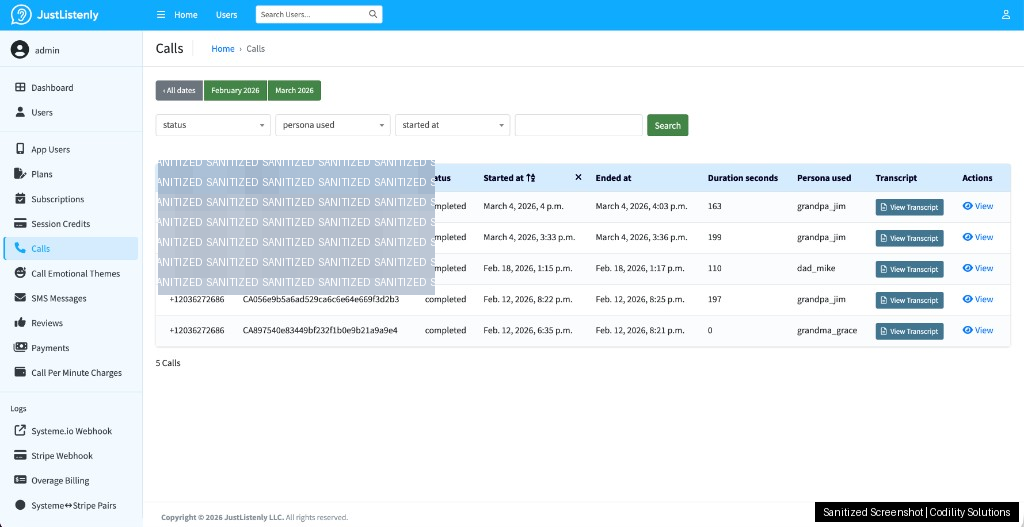
- User management: search by phone number, view call history, adjust session credits manually
- Transcript viewer: read full conversation logs in a modal overlay -- useful for quality review and dispute resolution
- Subscription management: view and cancel active subscriptions
- Payment audit: every webhook from Systeme.io and Stripe is logged with request/response data, processing time, and related IDs -- no black boxes in the payment flow
- Plan management: adjust pricing, session counts, and plan visibility without a deployment
All core models are read-only in the admin to prevent accidental data modification. The only full CRUD access is for Django admin user accounts.
Operations Dashboard Screenshots (Sanitized)
Below are real dashboard views from JustListenly operations. We masked personal details and sensitive identifiers before publishing these images.
The Stack
- Backend: Node.js / Express -- handles all Twilio webhooks and real-time call logic
- Voice: Twilio -- call routing, IVR, DTMF input, SMS delivery
- TTS: ElevenLabs -- natural voice synthesis with per-persona voice profiles
- AI: OpenAI -- conversation generation and emotional theme extraction
- Database: PostgreSQL with Prisma ORM -- 11 core tables covering users, credits, calls, subscriptions, payments, and audit logs
- Cache: Redis -- plan data and session state
- Payments: Stripe -- checkout, subscriptions, and overage billing
- Admin: Django with Jazzmin theme
- Infrastructure: Docker, PM2, Nginx
What Shipped
Phase 1 and Phase 2 together delivered a complete, production-ready product:
- Sub-2-second voice response latency in a phone call environment
- Four distinct AI personas with distinct voices and personalities
- Crisis detection with immediate 988 transfer
- Session-based subscription system with FIFO credit consumption
- Systeme.io to Stripe payment pipeline with heuristic matching and full audit logging
- Explicit-consent continuation billing at $0.97/minute with volume-adjusted prompts
- Emotional theme extraction and cross-call memory
- Five automated SMS workflows with opt-out handling
- Full-featured Django admin panel for non-technical operators
- 67+ unit tests and integration test coverage across all core services
What This Project Demonstrates
JustListenly is not a simple chatbot with a phone number attached. It is a product with genuine emotional design goals, a multi-platform payment architecture, and operational requirements that need non-technical staff to manage it daily.
The engineering challenge was not any single component -- Twilio, ElevenLabs, and Stripe are all well-documented. The challenge was integrating them into a system where the latency, tone, billing, and memory all work together in a way that feels seamless to the caller and manageable for the operator.
That is the gap between a prototype and a product. Closing it is what we build for.